Author's: Leili Javadpour, Mehdi Khazaeli and Gerald M. Knapp
Pages: [81] - [98]
Received Date: August 4, 2016
Submitted by:
DOI: http://dx.doi.org/10.18642/ijamml_7100121700
Anaphora resolution is the problem of resolving references of pronouns
to antecedents (previously mentioned noun phrases) in text documents.
It is a fundamental preprocessing step in text understanding
(semantic) applications, including dialogue and story understanding,
document summarization, information extraction, machine translation,
and recognizing entailment relations in text. We propose a set of
computational and linguistic features to resolve the pronominal
anaphora in text documents for a machine learning approach. The system
was evaluated on the BBN Pronoun Coreference and Entity Type Corpus,
and an F-measure of 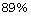 was obtained. The system was also tested
on different genre of document and the performance is compared with
the result of the annotated corpus.
was obtained. The system was also tested
on different genre of document and the performance is compared with
the result of the annotated corpus.
anaphora resolution, coreference, pattern recognition, machine learning, natural language processing.
